
On September 29, 2025, DeepSeek introduced a new experimental model, V3.2-expto tackle a major challenge in AI: the high cost of inference.
Instead of focusing on scale, the model offers efficiency. Its central feature, Sparse Attention, promises to reduce costs for long-context operations by nearly half.
Also read: Deepseek Could Be the New OpenAI
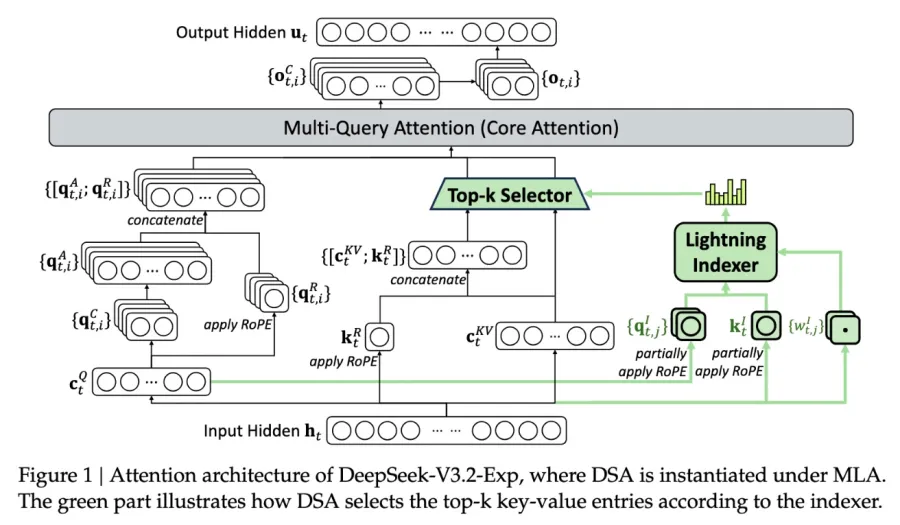
Sparse Attention
The new method uses a two-step approach. First, a “lightning indexer” selects the most relevant parts of the input.
Next, a “fine-grained token selection system” identifies the key tokens within those parts. This layered process reduces the volume of data the system must process at once.
This result is a leaner and faster model that limits server strain while preserving accuracy. The method mirrors how people scan documents, skipping filler and concentrating on important details.
Lowered AI Costs
Inference costs remain a significant issue in AI adoption as each query requires computing resources, which directly drive up expenses.
These costs can escalate quickly when long texts are involved. DeepSeek reports that V3.2-exp can cut the price of an API call by as much as 50 percent in long-context cases.
While these numbers are preliminary, the model is open-weight and available on Hugging Face. Independent researchers will soon test and verify the claims.
This could benefit startups, universities, and nonprofits as lower costs mean more access.
Smaller players in the AI space could build products and services once limited to well-funded organizations. This opens the door to wider innovation.
DeepSeek’s Trajectory
Earlier in 2025, the company drew notice with its R1 model, which used reinforcement learning to reduce training expenses.
Although R1 did not reshape the field, it signaled a willingness to challenge norms. The V3.2-exp release builds on that approach.
Instead of chasing ever-larger models, DeepSeek focuses on efficiency. In the broader U.S.-China AI rivalry, this strategy highlights an alternative to scale-driven development.