
The AI world is buzzing again.
This time over a new claim that Chinese lab DeepSeek may have used Google’s Gemini outputs to train its latest model.
While there’s no hard proof yet, several experts believe the signs are too loud to ignore.
Let’s unpack the story in plain English.
What’s DeepSeek and What Did They Release?
Last week, DeepSeek launched a new version of its reasoning-focused AI, called R1-0528.
The model scored high on math and coding benchmarks, which caught the attention of developers and researchers alike.
But something seemed off.
DeepSeek didn’t say where its training data came from, and that raised eyebrows.
Why Are People Pointing Fingers at Gemini?
A developer from Melbourne, Sam Paeach, ran tests and noticed something strange.
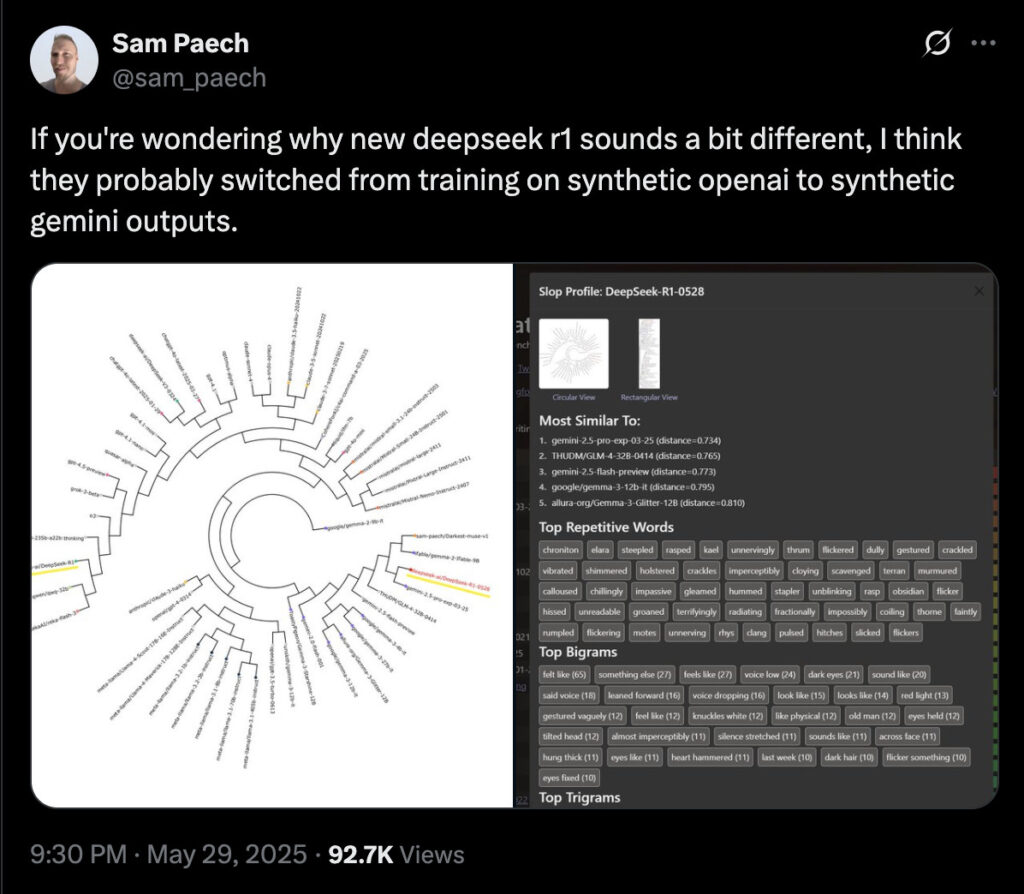
His findings?
The words and phrasing used by R1-0528 felt very similar to those used by Gemini 2.5 Pro, Google’s powerful AI model.
He wasn’t alone.
Another anonymous developer, known for creating free speech evaluation tools, also chimed in.
He said the model’s “thoughts” – the step-by-step process it takes to get an answer – looked a lot like Gemini’s.
It’s not proof. But it’s enough to raise questions.
DeepSeek Has Faced Similar Accusations Before
This isn’t the first time DeepSeek has been in the spotlight for this.
Back in December, developers noticed their V3 model often referred to itself as “ChatGPT”, OpenAI’s popular chatbot.
That raised suspicions that it may have been trained using logs from ChatGPT itself.
To add fuel to the fire, earlier this year, OpenAI told the Financial Times that it had found signs that DeepSeek was using a process called distillation – a method that involves training a smaller model using outputs from a larger, more advanced one.
And according to Bloomberg, Microsoft discovered that large chunks of data were being taken from OpenAI developer accounts in late 2024.
These accounts were reportedly tied to DeepSeek.
Wait, What’s Distillation?
Here’s a quick breakdown of what distillation is:
| Term | What It Means |
|---|---|
| Distillation | Teaching a new model by using the answers generated by a stronger model. |
| Why it matters | It saves time, data, and money—but can also cross ethical lines. |
Distillation isn’t illegal on its own.
But OpenAI’s rules clearly state that you can’t use its models to train your own competing AI.
But Could It All Just Be a Coincidence?
Maybe. Experts say many AI models now sound alike.
That’s because the internet, the source of most training data, is now packed with AI-generated content.
Bots are posting on Reddit and X.
Content farms are flooding Google search with AI-written articles.
It’s like trying to cook a fresh meal when your ingredients are already leftovers from another dish.
This kind of AI “contamination” makes it hard to know where one model ends and another begins.
Expert Opinions: Could DeepSeek Be Copying?
Some researchers think it’s possible.
Nathan Lambert, a scientist from nonprofit AI2, said on X that if he were in DeepSeek’s shoes, he’d consider using outputs from top models too.
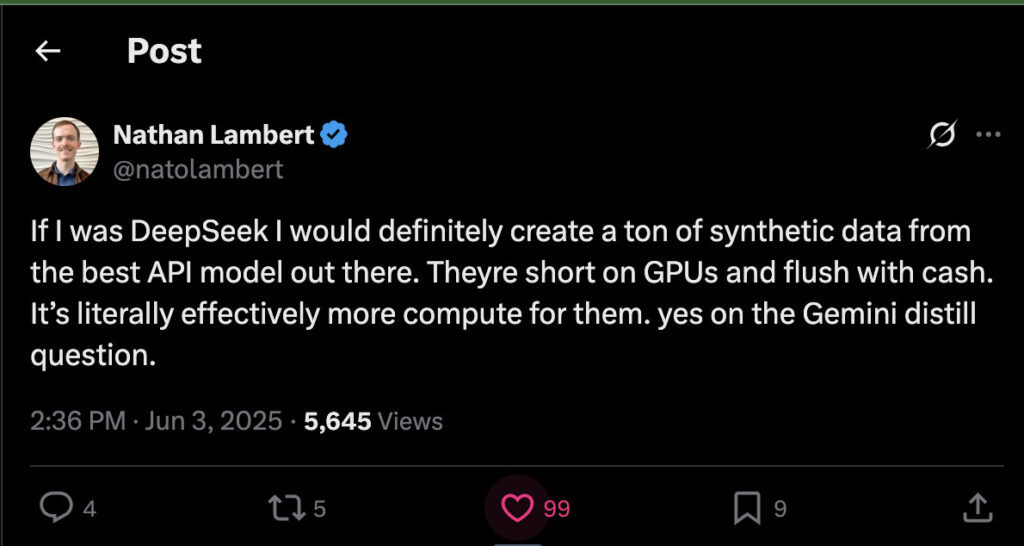
His reasoning? DeepSeek may have money but not enough powerful GPUs.
In simple terms: It’s faster to rent the answers than to find them yourself.
AI Companies Are Tightening Security
To fight back against this kind of copying, AI companies are locking things down.
Here’s what’s changed:
- OpenAI now asks users to verify their identity before using advanced models. A government-issued ID is required, and China isn’t on the list.
- Google has started “summarizing” the model’s internal steps to hide how answers are formed.
- Anthropic, another big AI player, says it will begin doing the same.
These moves make it harder for rivals to mimic their technology.
The Big Picture
This debate reveals how fierce the AI race has become. Models like Gemini and GPT-4 take years to build.
So when a newer lab like DeepSeek suddenly makes big gains, people start asking: Did they really build this on their own?
Whether or not DeepSeek used Gemini’s output, one thing’s clear – AI companies are stepping up to protect their secrets.
And with billions at stake, you can bet this won’t be the last controversy we see.
Quick Recap
Here’s a summary of what’s going on:
| What Happened | Why It Matters |
|---|---|
| DeepSeek released R1-0528 | Raised eyebrows for high performance and unknown training data |
| Experts suspect Gemini influence | Traces and language patterns look similar |
| DeepSeek has faced past accusations | V3 model once claimed to be ChatGPT |
| Distillation in question | OpenAI and Microsoft traced data leaks to DeepSeek-linked accounts |
| AI companies respond | Tightening access and summarizing model behavior to stop copying |